Generalized chi-squared distribution
In probability theory and statistics, the specific name generalized chi-squared distribution (also generalized chi-square distribution) arises in relation to one particular family of variants of the chi-squared distribution. There are several other such variants for which the same term is sometimes used, or which clearly are generalizations of the chi-squared distribution, and which are treated elsewhere: some are special cases of the family discussed here, for example the noncentral chi-squared distribution and the gamma distribution, while the generalized gamma distribution is outside this family. The type of generalisation of the chi-squared distribution that is discussed here is of importance because it arises in the context of the distribution of statistical estimates in cases where the usual statistical theory does not hold. For example, if a predictive model is fitted by least squares but the model errors have either autocorrelation or heteroscedasticity, then a statistical analysis of alternative model structures can be undertaken by relating changes in the sum of squares to an asymptotically valid generalized chi-squared distribution.[1] More specifically, the distribution can be defined in terms of a quadratic form derived from a multivariate normal distribution.
Contents |
Definition
One formulation of the generalized chi-squared distribution is as follows.[1] Let z have a multivariate normal distribution with zero mean and covariance matrix B, then the value of the quadratic form X=zTAz, where A is a matrix, has a generalised chi-squared distribution with parameters A and B. Note that there is some redundancy in this formulation, as for any matrix C, the distribution with parameters CTAC and B is identical to the distribution with parameters A and CBCT. The most general form of generalized chi-squared distribution is obtained by extending the above consideration in two ways: firstly, to allow z to have a non-zero mean and, secondly, to include an additional linear combination of z in the definition of X.
Note that, in the above formulation, A and B need not be positive definite. However, the case where A is restricted to be at least positive semidefinite is an important one.
For the most general case, a reduction towards a common standard form can be made by using a representation of the following form:[2]
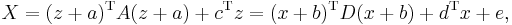
where D is a diagonal matrix and where x represents a vector of uncorrelated standard normal random variables. An alternative representation can be stated in the form:[3][4]
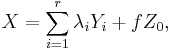
where the Yi represent random variables having (different) noncentral chi-squared distributions, where Z0 has a standard normal distribution, and where all these random variables are independent. Some important special cases relating to this particular form either omit the additional standard normal term and/or have central rather than non-central chi-squared distributions for the components of the summation.
Practical implementation
Computer code for evaluating the cumulative distribution function of the generalized chi-squared distribution has been published.[2][4] but some preliminary manipulation of the parameters of the distribution is usually necessary.
Other applications
The following application arises in the context of Fourier analysis in signal processing, Renewal theory in Probability theory, and multi-antenna systems in wireless communication. The common factor of these areas is that the sum of exponentially distributed variables is of importance (or identically, the sum of squared magnitudes circular symmetric complex Gaussian variables).
If 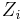 are k independent, circular symmetric complex Gaussian random variables with mean 0 and variance
are k independent, circular symmetric complex Gaussian random variables with mean 0 and variance 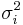 , then the random variable
, then the random variable
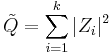
has a generalized chi-squared distribution of a particular form. The difference from the standard chi-squared distribution is that are complex and can have different variances, and the difference from the more general generalized chi-squared distribution is that the relevant scaling matrix A is diagonal. If 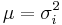 for all i, then
for all i, then 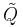 becomes a
becomes a 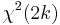 scaled by
scaled by 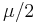 , also known as the Erlang distribution. If have distinct values for all i, then has the pdf[5]
, also known as the Erlang distribution. If have distinct values for all i, then has the pdf[5]
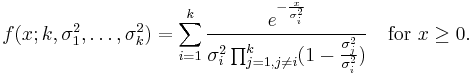
If there are sets of repeated variances among , assume that they are divided into M sets, each representing a certain variance value. Denote 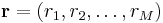 to be the number of repetitions in each group. I.e., the mth set contains
to be the number of repetitions in each group. I.e., the mth set contains 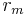 variables that have variance
variables that have variance 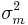 . it represents an arbitrary linear combination of
. it represents an arbitrary linear combination of 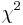 random variables with different degree of freedoms:
random variables with different degree of freedoms:
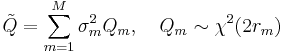
The pdf of becomes[6]
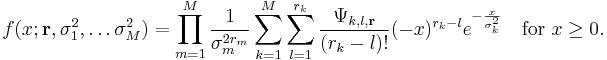
where
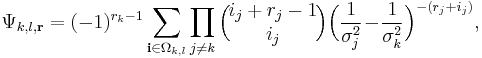
with ![\mathbf{i}=[i_1,\ldots,i_M]^T](/2012-wikipedia_en_all_nopic_01_2012/I/cf292e9b639daf81f227dda70f660a4b.png) from the set
from the set 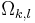 of all partitions of
of all partitions of  (with
(with 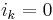 ) defined as
) defined as
![\Omega_{k,l} = \Big\{ [i_1,\ldots,i_m]\in \mathbb{Z}^m;
\sum_{j=1}^M i_j \!= l-1, i_k=0, i_j\geq 0 \,\, \forall j
\Big\}.](/2012-wikipedia_en_all_nopic_01_2012/I/c5203bfb5dcd888c892bfbe29b682f3d.png)
References
- ^ a b Jones, D.A. (1983) "Statistical analysis of empirical models fitted by optimisation", Biometrika, 70 (1), 67–88
- ^ a b Sheil, J., O'Muircheartaigh, I. (1977) "Algorithm AS106: The distribution of non-negative quadratic forms in normal variables",Applied Statistics, 26, 92–98
- ^ Davies, R.B. (1973) Numerical inversion of a characteristic function. Biometrika, 60 (2), 415–417
- ^ a b Davies, R,B. (1980) "Algorithm AS155: The distribution of a linear combination of χ2 random variables", Applied Statistics, 29, 323–333
- ^ D. Hammarwall, M. Bengtsson, B. Ottersten, Acquiring Partial CSI for Spatially Selective Transmission by Instantaneous Channel Norm Feedback, IEEE Transactions on Signal Processing, vol 56, pp. 1188-1204, March 2008.
- ^ E. Björnson, D. Hammarwall, B. Ottersten, Exploiting Quantized Channel Norm Feedback through Conditional Statistics in Arbitrarily Correlated MIMO Systems, IEEE Transactions on Signal Processing, vol 57, pp. 4027-4041, October 2009